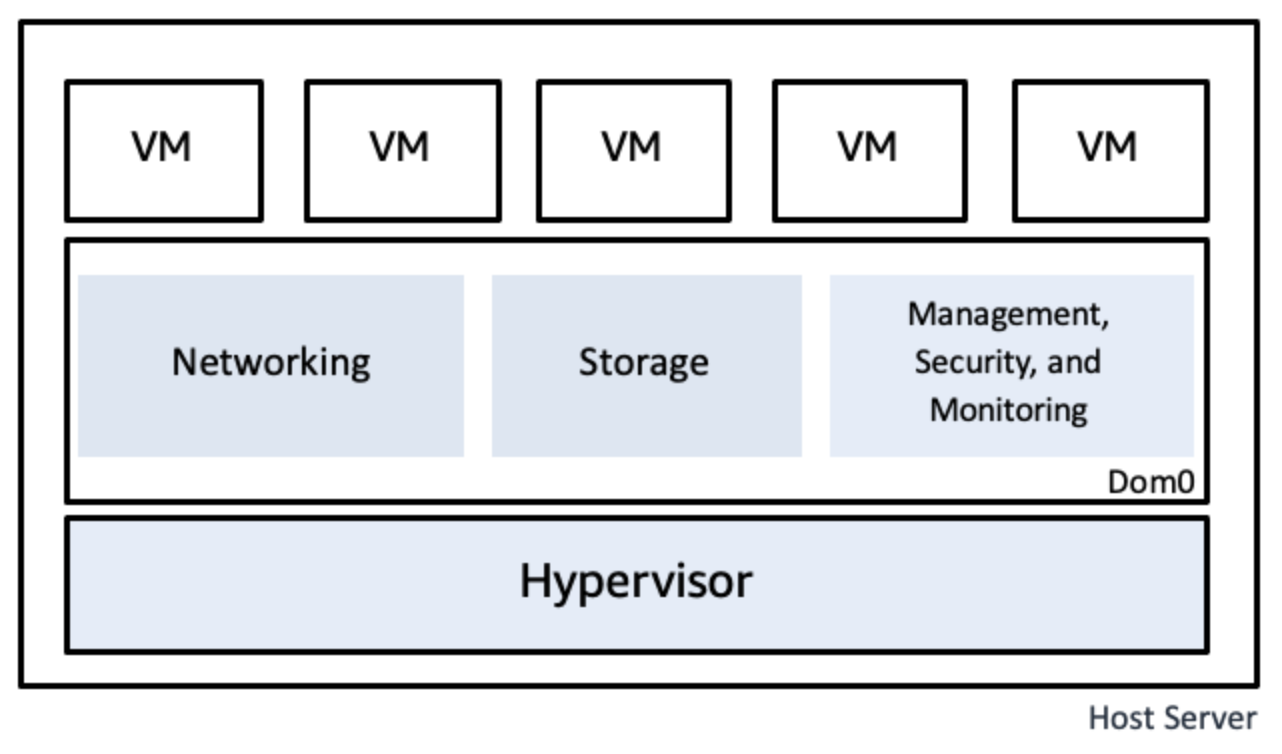
虚拟机
借助虚拟化技术,用户能以单个物理硬件系统为基础创建多个模拟环境或专用资源。“Hypervisor” (虚拟机监控程序)的软件可直接连接到硬件,从而将一个系统划分为不同的、单独安全环境,即虚拟机(VM)。
Type 1 & Type 2 虚拟机监控程序
第 1 类虚拟机监控器位于裸机服务器之上,可以直接访问硬件资源。因此,第 1 类虚拟机监控器也称为裸机虚拟机监控器。
相比之下,第 2 类虚拟机监控器是安装在主机操作系统上的应用程序。此类虚拟机监控器也称为托管或嵌入式虚拟机监控器。
- 第 1 类虚拟机监控器或裸机虚拟机监控器直接与底层计算机硬件交互。裸机虚拟机监控器直接安装在主机的物理硬件上,而不是通过操作系统安装。
- 第 2 类虚拟机监控器或托管虚拟机管理监控器通过主机的操作系统与底层主机硬件进行交互。第 2 类虚拟机监控器安装在计算机上,在其中作为应用程序运行。
- Hypervisor属于协调层,同时运行多个虚拟机
JavaScript
比较熟悉了,简单写几个Tutorial的点
- 原型链(Prototype Chain):这个机制的关键点在于当你尝试访问一个对象的属性或方法时,如果该对象本身没有这个属性或方法,JavaScript引擎就会沿着这个对象的原型链向上查找,直到找到这个属性或方法或到达原型链的末端。
object.getPrototypeOf() - function也是一个object
- undefine和null是不同的类型,
undefine === nullFalseundefine == nullTrue
- 声明变量别用var。变的就用let,不变就用const,舍弃var
<button class=" bg-green-500 hover:bg-green-700 text-white font-bold py-2 px-4 rounded transform transition hover:scale-110"> Shop Online </button> <!-- py-2 px-4 指x和y方向上的padding大小-->- map方法
const numbers = [1, 2, 3, 4]; const doubled = numbers.map(num => num * 2); console.log(doubled); - reduce方法
const numbers = [1, 2, 3, 4]; const sum = numbers.reduce((acc, curr) => acc + curr, 0); console.log(sum);
容器
容器是虚拟机的轻量级替代产品,易于创建和管理。 容器封装了应用程序及其所需要的依赖,位于操作系统的内核之上。从应用程序的角度来看,容器就是虚拟机,只不过”更轻“。
Docker
Docker是最令人熟知的容器化技术。
在Docker中,容器由镜像创建,镜像由Dockerfile编写
# 拉一个Ubentu镜像
$ docker pull ubuntu:latest
# 运行这个容器
$ docker run -it ubuntu:latest /bin/bash
写一个Dockerfile,创建docker镜像👇
# 指定基础镜像
FROM ubuntu : latest
# 创建shell脚本并将“echo Hello, World!”写入脚本
RUN echo " echo Hello , World ! " > / hello - world . sh
# 为文件添加执行权限
RUN chmod + x / hello - world . sh
# 指定容器启动时默认执行的命令。
CMD [ " / hello - world . sh " ]
运行Docker👇
# Build the Docker image
$ docker build -t hello - world .
# Run the Docker container
$ docker run hello - world
常用Docker命令
# 查看镜像
docker images
# 查看正在运行的容器
docker ps
# 查看所有容器,包括停止的
docker ps -a
# 停止容器
docker stop [containerId]
# 删除容器
docker rm [containerId]
# 删除镜像
docker rmi ubentu:lastest
image(镜像)和container(容器)的区别
最根本的区别在于它们操作的对象不同。docker images关注的是Docker镜像,这些镜像是容器的模板。而docker ps关注的是由这些镜像创建的容器的实际运行状态
Docker和Linux Kernel
- 共享Kernel:容器利用宿主机的内核,它们不需要像虚拟机那样虚拟化硬件和运行自己的操作系统内核。这意味着容器非常轻量,启动快,占用资源少。
- 隔离性:尽管容器共享宿主机的内核,但它们通过Linux内核的特性如cgroups(控制组)和namespaces(命名空间)来实现进程、网络、文件系统等方面的隔离。这使得容器表现得就像是在独立的环境中运行一样。
- Kernel依赖性:因为容器直接依赖于宿主机的Linux内核,所以容器化的应用必须与宿主机的内核兼容。这也意味着,如果你需要特定的内核特性或版本,你的宿主机必须运行支持这些特性的Linux内核。
Linux内核支持容器化依赖以下三个功能
- Namespaces 命名空间能够隔离和分割系统资源,使得进程只能看到自己命名空间内的资源。Linux提供了多种类型的命名空间,每种类型都隔离一组特定的系统资源。例如,PID(进程ID)命名空间隔离进程ID,使得不同命名空间中的进程可以有相同的PID,而网络命名空间隔离网络接口和路由表,等等。这意味着在一个容器中运行的进程可以有自己的网络接口和IP地址,就好像它在自己的虚拟网络中一样。
- Control groups 控制组允许对进程群组进行资源控制、限制、分配和监视。通过cgroups,系统管理员可以指定CPU、内存、磁盘I/O等资源的限制,确保某个容器不会使用过多的资源,从而影响到系统上其他的进程或容器。
- Union File Systems 联合文件系统是一种特殊的文件系统,它可以将多个不同的文件系统“叠加”在一起,形成一个统一的文件系统视图。这意味着可以将不同的目录层次结构合并成一个目录视图,对于容器而言,这使得可以通过叠加不同的层(每层包含文件的变化)来构建容器的文件系统。Docker中的镜像和容器层就是使用联合文件系统技术实现的。这种方式使得容器镜像变得更加高效,因为多个容器可以共享同一个基础镜像的只读层,而每个容器的变化都存储在自己的可写层中。
安全
Vulnerabilities and the Zero-Day Problem
零日问题(Zero-day vulnerability)指的是一种安全漏洞,这种漏洞在被发现后还没有得到修复,攻击者可以利用这个漏洞来进行攻击,而且被攻击的目标并没有提前意识到这个漏洞的存在。因此,攻击者可以在漏洞被公开之前利用它,这就是为什么称之为“零日”,因为漏洞被发现的那一天就被利用了。
主机防御
通常来讲,我们无法阻止零日攻击,但是可以降低零日攻击带来的损害,这就涉及到主机防御(host defences)。
最小权限原则
The principle of least privilege (PoLP),其核心思想是任何用户、程序或系统进程在执行某项操作时,应该仅具有完成该操作所需的最低权限或最小权限集。最小权限原则的目的是减少安全风险并提高系统的安全性。它有助于防止恶意软件扩散,减少系统漏洞的攻击面,并限制对敏感数据的访问,从而降低数据泄露或损坏的风险。
权限提升
权限提升(Privilege Escalation)是指在计算机安全领域中,通过利用系统中的漏洞、配置错误或设计缺陷,未授权的用户、程序或进程获得了比原本分配给它们的更高的访问权限或功能的过程。
- 垂直权限提升 垂直权限提升,也称为提权,发生在当低权限用户或程序获取高权限级别(如管理员或root权限)的能力时。这种类型的权限提升允许攻击者执行通常只有系统管理员才能执行的操作,如访问敏感文件、修改系统设置或安装恶意软件。
- 水瓶权限提升 水平权限提升发生在当用户或程序从一个普通账户跳转到另一个具有相同权限级别的账户时。虽然攻击者没有获取更高的权限级别,但他们可能能够访问特定的、原本不应该访问的数据或功能。例如,一个普通用户通过水平权限提升成为另一个普通用户,可能访问到第二个用户的私人文件或数据。
Sandboxes
沙盒(Sandbox)是一种安全技术,旨在在一个隔离的环境中运行程序或代码,以防止该程序或代码对宿主系统造成潜在的损害或不安全的影响。沙盒提供了一个严格控制的执行环境,其中的应用程序可以执行,但只能访问明确允许的资源和操作。
沙盒的特点
- 隔离性:沙盒环境与宿主系统及其他沙盒环境隔离,以防止程序间的相互影响和对宿主系统的潜在破坏。
- 资源控制:沙盒限制了运行在其中的程序所能访问的系统资源(如文件系统、网络、系统配置等),并可以监控和控制对这些资源的访问。
- 操作限制:沙盒通常限制程序执行的操作类型,比如禁止修改系统设置或访问敏感数据。
- 监控与审计:沙盒环境可以监控程序的行为,记录程序执行过程中的所有操作,为安全分析和审计提供依据。
自主访问控制
Discretionary Access Control 是一种访问控制模型,它允许资源的拥有者或拥有者授权的用户控制对资源的访问。在DAC模型中,用户可以根据自己的判断(即“自主”地)决定谁可以访问特定的资源。
特点
- 所有权和权限:在DAC系统中,资源的访问权限通常基于资源的所有权。所有者有权设置或更改对其资源的访问权限。
- 灵活性:DAC提供了较高的灵活性,允许用户根据需要分享和限制资源的访问。这种模型适合需要频繁更改权限设置的环境。
- 用户控制:用户(或用户组)可以直接控制对其拥有的资源的访问,而不是由中央政策或管理员决定。
一些指令👇
# 查看文件权限
$ ls -l filename
# 更改文件权限,把文件改成可读可写可执行
$ chmod 755 filename
# root user执行,给管理员权限
$ sudo chmod 755 filename
在Linux中,文件权限由三位数组成,可读是4,可写是2,可执行是1。所以755意思
- 7: (r+w+x) 有可读可写可执行的权限。
- 5: (r+x) 当前分组有可读+可执行的权限,但没有可写的权限。
- 5: (r+x) 其他人也有可读+可执行的权限,但没有可写的权限。
强访问控制
Mandatory Access Control (MAC)。它根据中央权威的决策而不是用户的自主决定来限制对系统资源的访问。与自主访问控制(Discretionary Access Control,DAC)相比,MAC提供了更为严格和详细的控制,确保只有授权用户才能访问特定的信息或资源。
特点
- 中央管理:在MAC策略中,访问控制策略由系统管理,而不是由资源的所有者或用户设置。这意味着用户不能更改他们不拥有的文件或资源的访问控制设置。
- 安全标签:MAC系统使用安全标签来标识主体(如用户或进程)和客体(如文件、目录或设备)。这些标签包含了安全级别或分类信息,如机密、秘密等。
- 访问决策:访问控制决策基于比较主体的安全级别与客体的安全级别。只有当主体的安全级别足以访问客体时,访问才会被允许。
- 策略强制执行:MAC强制执行预定义的安全策略,这些策略旨在保护信息不被未授权的访问、泄露或篡改。
在Red Hat Enterprise Linux, SELinux作为解决方案实现MAC。
SELinux
这是一个在Linux内核中实现的安全框架
SELinux有三种执行模式
- enforcing
- 这是SELinux的默认模式。在这种模式下,SELinux会强制执行其安全策略,限制进程访问资源。如果一个进程尝试执行一个不被允许的操作,SELinux会阻止这个操作并记录相应的违规信息。这意味着,如果SELinux的策略不允许某个操作,那么这个操作就不能被执行,无论执行它的用户或进程有多高的权限。
- permissive
- 在这种模式下,SELinux同样会检查所有的操作,判断它们是否违反了安全策略,但它不会实际阻止任何操作。相反,它会记录所有被检测到的违规行为,就像在强制模式下那样。这个模式对于调试SELinux策略非常有用,因为它允许管理员看到哪些操作会被阻止,而不需要实际上阻止这些操作,这样可以在不影响系统正常运行的情况下测试和修改策略。
- disabled
- 在这种模式下,SELinux被完全禁用,不会检查或限制任何操作。这意味着系统的安全将完全依赖于传统的离散访问控制(DAC)机制,如文件权限等。禁用SELinux模式通常不推荐,因为这会降低系统的安全性。然而,在某些特定场合,比如兼容性测试或者在系统上运行不兼容SELinux的软件时,可能需要暂时禁用SELinux。
Labelling in SELinux
在SELinux(Security-Enhanced Linux)中,标签(Labeling)是实现其安全策略的核心机制之一。SELinux通过为系统中的每个对象(如文件、进程、用户等)和主体(通常指用户或进程)分配安全标签来工作。这些标签用于定义和控制主体对对象的访问权限,依据的是定义在SELinux策略中的规则。
作用:SELinux通过匹配主体的标签与对象的标签来决定是否允许某个访问请求。这种基于标签的访问控制机制允许SELinux实现强制访问控制(MAC),即使在主体拥有足够Linux传统权限(如root)的情况下,也能限制对敏感资源的访问。
SELinux的安全标签通常由以下几部分组成:
- 用户(User):不同于Linux系统的用户,SELinux用户代表的是安全策略中的一个元素,用于控制访问权限。它定义了一组可以执行的角色。
- 角色(Role):角色用于将权限集合与SELinux用户和类型关联起来。进程必须拥有对应的角色才能访问某些类型的对象。
- 类型(Type):也称为域(Domain)对于进程而言。类型是SELinux中最重要的部分,它为对象和主体定义了具体的安全策略。通过类型,SELinux策略可以非常细致地控制哪些主体可以访问哪些对象。
- 敏感度(Sensitivity)/清晰度(Clearance):这些是用于多级安全(MLS)策略的可选部分,它们定义了数据的敏感度级别和主体的访问级别。
Tutorial for SELinux
- SELinux标签在文件管理系统中的作用
- Every process has a lable, and every file/directory object in the operating system has a label
- Network ports, devices, and potentially host names also have labels assigned to them
- Rules are written to control the access of a process label to an object lable
- The kernel enforces these rules
- What is the purpose of ls -Z
- General information about the file, such as permission, owner, size, and modification time.
- SELinux security context for each file and directory.
chcon -t https_sys_content_t /var/www/html/index.html-t标签的作用和chcon的作用- chcon is a command to change the security context. like “change context”
- -t indicates the type, in this case, the SELinux type is https_sys_content_t
- SELinux中enforcing和permissive模型的区别
- In enforcing mode, SELinux policies are enforced and access violations are logged.
- In permissive mode, SELinux policies are not enforced but access violations are logged.
- 怎么查看SELinux布尔运算的状态(以httpd_can_network_connect为例)
$ getsebool httpd_can_network_connect $ setsebool httpd_can_network_connect on // 暂时更改,重启后不保持连接 $ setsebool -P httpd_can_network_connect on // P是permanent,重启后依然保持连接 audit2allow指令的作用,怎么用它排除违反SELinux策略的故障- Used to analyse permission issues caused by SELinux. It mainly reads policy violations from SELinux’s audit logs and then generates policy rules that allow these behaviours.
audit2allow -w -aReads audit logs and generates comprehensible descriptions explaining why certain operations were denied.
- How do you set selinux to permissive mode for a specific daemon, such as httpd, without affecting the global SELinux mode?
- 确认daemon的 SELinux 类型,
ps -eZ | grep httpd - 设定daemon为permissive模式,
sudo semanage permissive -a httpd_t - 验证设置,
semanage permissive -l - 通过以上步骤就可以单独为 httpd 守护进程设置 SELinux 为 permissive 模式,而不改变系统的全局 SELinux 状态。
- 确认daemon的 SELinux 类型,
- How do you undo this change
- 要撤销之前将特定守护进程如 httpd 设为 permissive 模式的更改,您需要将它从 permissive 类型列表中移除,使其重新受到 enforcing 模式的控制。
- 移除守护进程的 permissive 类型设置,
sudo semanage permissive -d httpd_t - 验证是否移除成功,
semanage permissive -l - 重启守护进程
sudo systemctl restart httpd
- IPv4地址是192.168.100.14,网络掩码是255.255.255.0,怎么计算network address
- 把IPv4和网络掩码都转成二进制,and操作,得出的结果再转回十进制,得出的结果就是network address
- 这里计算好的network address是192.168.100.0
- 上面提到的这个网络能支持多少个主机?
- 根据网络掩码,最后一个八位组是为主机分配的,其中有8个0,可配置主机数就是256个,但是要减去一个网络地址(192.168.100.0)和一个广播地址(192.168.100.255),可配置主机数就是254个
Ansible
Inventory file
使用Ansible之前,Inventory 文件是一个定义了可被 Ansible 管理的所有主机及其组的关键组件。这些文件可以是静态的或动态的,允许 Ansible 知道它可以连接哪些服务器,以及这些服务器如何组织。
leafs:
hosts:
leaf01:
ansible_host: 10.16.10.11
leaf02:
ansible_host: 10.16.10.12
spines:
hosts:
spine01:
ansible_host: 10.16.10.13
spine02:
ansible_host: 10.16.10.14
有了inventory file之后,可以使用ansible命令行工具在主机上运行inventory中的指令,例如使用ping检查inventory中所有主机的连接。
ansible -i hosts.ini local -m ping
Playbook
Playbook能描述比命令行更复杂的配置,例如:
---
- name: Ping all hosts
hosts: all
tasks:
- name: Check connectivity
ping:
loop: "{{ range(1, 4) | list }}"
loop_control:
label: "Ping number {{ item }}"
Playbook的结构
Playbook由以下几个部分组成
- Plays: 运行任务的基本单元。每个 Play 指定了目标主机、需要执行的 Tasks,以及可能的一些变量设置。一个 Playbook 可以包含一个或多个 Play,每个 Play 为不同的主机或主机组定义操作。
- Tasks: 是 Play 中执行的具体操作。每个 Task 通常调用一个 Ansible Module,用于执行特定的操作,如安装包、编辑文件或同步目录等。
- Modules: 是 Ansible 的功能单元,它们可以独立执行或由 Task 调用。每个 Module 设计为处理特定的任务,如管理系统包(yum, apt)、操作文件系统(file, copy)等。
- Become: 是一种权限提升机制,允许用户任务在目标主机上以其他用户的权限执行。这在需要执行管理员权限的操作时非常有用。例如,使用
become: yes可以使任务以 root 用户执行。 - When: 一种条件语句,用于控制 Tasks 的执行。只有当指定的条件满足时,相关的 Task 才会执行。
- Register: Register用于捕获 Task 的输出并将其存储到一个变量中。
- Loops: 允许在 Playbook 中重复执行一个 Task 多次,每次可以使用不同的数据。这对于执行批量操作(如创建多个用户、安装多个软件包等)非常有用。
Anything as a service
云服务商提供对云的三级访问
- Infrastructure as a Service(IaaS): IaaS 是一种提供虚拟化的计算资源作为服务的模型。客户在 IaaS 环境中租用 IT 基础设施,如服务器、虚拟机(VMs)、存储、网络和操作系统,来自一个云提供商。这种服务模式允许用户通过互联网远程访问这些资源,而无需购买和维护物理服务器。
- Platform as a Service(PaaS): PaaS 提供了除了底层基础设施之外,还包括了软件开发工具、库、数据库管理系统和更多开发者工具的集合。用户可以在这个平台上构建、部署和管理应用,无需关心操作系统、软件更新、存储或基础设施。
- Software as a Service(SaaS): SaaS 是一种软件分发模型,其中应用软件被托管在云中,并通过互联网向最终用户提供。用户不需要安装任何软件,只需通过网络访问这些应用。SaaS 提供商通常会提供应用的维护、支持、安全和性能更新。
Everything as Code
- Infrastructure as Code(IaC): 通过代码来管理和配置基础设施(如服务器、网络、虚拟机等),使用脚本或声明性文件定义基础设施,以便可以自动创建、部署和管理基础设施资源。
- Configuration as Code(CaC): 使用自动化脚本或配置管理工具(如 Ansible、Chef、Puppet)来管理和部署软件配置。这样做可以确保系统配置的一致性和可重复性。
Ansible Variables
Networking
Protocol Stacks
协议是一组规则和标准,用于定义数据在网络中的传输方式。这些规则包括数据如何被格式化、传输、接收,以及如何对错误进行响应。
网络协议栈,是一组工作在不同层次上的网络协议的集合。每一层都承担特定的网络通信子任务,通过层与层之间定义良好的接口相互作用。数据在一个层处理后,会传递到另一个层进一步处理,直到发送到网络上,接收方则按相反顺序处理数据。
两个主要的协议栈:OSI和TCP/IPTCP/IP
OSI模型
OSI模型有7层
- Layer 7: 应用层(Application),为应用软件提供网络服务,如 HTTP、FTP。
- Layer 6: 表示层(Presentation),数据的翻译、加密和压缩。
- Layer 5: 会话层(Session),管理用户会话和对话,两个节点之间以多次来回传输的形式持续交换信息。
- Layer 4: 传输层(Transport),提供端到端的通信服务,如 TCP 或 UDP。
- Layer 3: 网络层(Network),处理数据包的路由和转发。构建和管理多节点网络。
- Layer 2: 数据链路层(Data Link),处理帧的传输,错误检测和纠正。
- Layer 1: 物理层(Physical),处理原始的比特流传输。
TCP/IP栈
简化了OSI模型
- Layer 4: 应用层(Application),包含 OSI 的会话层、表示层和应用层的功能,处理所有高级的应用协议。
- Layer 3: 传输层(Transport),负责提供端到端的通信,主要使用 TCP 和 UDP。
- Layer 2: 互联网层(Internet),相当于 OSI 的网络层,主要使用 IP 协议。
- Layer 1: 网络接口层(Physical),等同于 OSI 的物理层和数据链路层,处理与物理网络的接口。
Protocols
两个要通信的计算机如何找到彼此?
首先介绍3种地址
- Domain name: https://google.com
- IP Address: 101.103.101.103
- MAC Address: 分配给网络接口控制器(Network Interface Controller)的唯一标识符。它在 OSI 模型的数据链路层(第 2 层)运行,允许网卡相互通信。
下面详细说明OSI模型中除了物理层的剩下六层
- Layer 2 & Ethernet
- 数据链路层直接通过网络交换机进行通信,而无需通过路由器。
- 以太网是数据链路层中最常见的一种技术标准,也是最普遍的局域网技术。
- 数据链路层负责将比特组织到以太网帧中,并确保在物理介质上的可靠传输。
- Ethernet Frame构成:Destination MAC, Source MAC, Type, Data, CRC
- Layer 3 & IP
- IPv4: 192.168.0.1 每一块数字都是由0-255的数字组成的。
- IPv6: 2001:0DB8:ABCD:EF01:2345:6789:ABCD:EF01 由8位组成,每一块都是一个4位16进制数据
- Layer 4 & TCP and UDP
- TCP又叫Transport Communication Protocol,这是一种面向连接的协议,提供可靠的、有序的和无差错的数据传输服务。它通过序列号、确认应答、重传机制、流量控制和拥塞控制等技术来保证数据传输的可靠性和完整性。
- UDP又叫User Dataram Protocol,UDP 不保证数据包的顺序、完整性或可靠性,也不进行流量控制或拥塞控制。它仅仅发送数据,并希望它们能到达目的地,但不保证它们一定会到达。
- Layer 6 & TLS(Transport Layer Security)
- TLS是一种加密协议,在计算机网络中用来提供通信安全,在表示层操作。主要用于在两个通信应用之间提供保密性和数据完整性的安全协议。它广泛用于互联网通信和在线数据传输,尤其是在Web浏览、电子邮件、即时通讯和其他数据交换的应用中。
- TLS Record是 TLS 的底层协议,负责封装不同的高层协议数据。它为传输提供两个基本服务:保密性和数据完整性。
- TLS 握手协议是建立 TLS 连接时最重要的部分,用于在两个通信端之间协商加密算法,验证对方身份,并交换密钥信息。这一过程发生在发送任何实际应用数据之前。
- Layer 7 & HTTP/HTTPS
- HTTP 使用UDP
- HTTPS(最后一个S代表Secure) 使用TLS或SSL。
Hosting
在网络架构中,Proxy是一个服务器,它作为客户端和其他服务器之间的中介。根据其配置和用途的不同,代理可以被分类为Forward Proxy和Reverse Proxy。
简单来讲,Forward Proxy被看作是客户端,代表用户向服务端发送请求;Reverse Proxy被看作是服务端,实际是将请求转发到后端服务器,再把服务器的响应返回给客户端。
如何生成一个self-signed certificate?
$ openssl req -x509 -nodes -days 365 -newkey rsa:2048 -out selfsigned.crt -keyout private.key -subj "/C=UK/ST=Merseyside/L=Liverpool/O=MyOrg/CN=www.example.com"
Storage
storage solutions分为以下三种
- Local Server Storage: 本地服务存储指的是服务器上的硬件驱动,这提供了快速的访问速度。但是这不适合云应用,因为一旦一个服务器宕机,我们需要重起一个新的主机,但是新的主机无法访问这些数据
- Network Attached Storage (NAS): NAS在一个RAID(数据存储虚拟化技术)配置中有多个硬盘驱动,他们作为共享驱动来被访问。NAS的主要缺点是如果单个组件宕机,所有数据都无法访问。
- Storage Area Network (SAN): 存储数据的计算机网络,由多个磁盘阵列,网络交换机和服务器组成。这种方式具备容错率,因为数据被复制存储在几个磁盘阵列上,如果某个磁盘宕机,数据仍然能被访问。容易扩展,添加额外的存储不会中断SAN。
数据库
- 关系型数据库
- NoSQL数据库
- 图数据库:每个节点和边都能存储任意数量的attributes。节点表示entities,边表示entities之间的关系。
- Neo4j:这是一款非常流行的图数据库。Neo4j使用的检索语言叫做Cypher。
CREATE (ee:Person {name: 'Emil', from: 'Sweden', kloutScore: 99})- ee是节点变量,Person是节点标签,{}包含了描述节点的性质
MATCH (ee:Person) WHERE ee.name = 'Emil' RETURN ee;
Typescript
基本类型
any类型会绕过系统的类型检查,但是过度使用any可能会造成错误代码难以追踪。unknown是any的更安全版本,因为更严格,unknown类型智能用于==, ===, !=, !==,除此以外都不可以,例如下面代码就会报错
let a: unknown = 30;
let c = a + 10; //这里会报错,因为unknown类型不支持+
bool类型的几种声明方式
let d: boolean = true
let e: true = true //这种声明后,以后只能是true,不能修改。
number类型的几种声明方式
let a: number = 10;
let b: 26.187 = 26.187;
let c: 50 = 40; // Error TS2322: Type '50' is not assignable to type '40'
bigint类型的几种声明方式,这里有一点需要注意:n后缀表示这是一个bigint类型的数值,而不是普通的number类型。100n表示数值一百。
let a = 1234n;
let b: bigint = 100n;
let c = 88.5n; //Error TS1353: A bigint literal must be an integer
symbol类型的几种声明方式。每次调用Symbol()都会生成一个新的、唯一的symbol。你可以选择性地给Symbol()函数传递一个描述字符串,这个字符串并不影响 symbol 的唯一性。
let a: symbol = Symbol('a')
let sym1 = Symbol("key1");
let sym2 = Symbol("key1");
console.log(sym1 === sym2); // 输出:false
对象类型
let a: object = {
b: 'x'
}
console.log(a['b'])
// 这部分声明了一个变量c,并且指定了c的类型为一个对象。这个对象的结构被明确定义:它必须包含一个键d,且该键的值类型为string
let c: { d : string } = {
d: 'y'
}
console.log(c.d)
// 两种容易碰到的报错情况
let a: { b: number }
a = {} // 报错,不能声明一个空对象
a = {
b: 1,
c: 2 // 报错,声明的时候没有c,所以会在c这个位置报错
}
那么不确定是个参数是否需要,或者调用的时候不一定会传入,怎么做?
let a: {
b: number
c?: string
[key: number]: boolean
}
a = {b: 1, 10: true}
a = {b: 1, c: 'd', 10: true}
声明的时候还可以吧变量写成readonly,这意味着一旦初始化后,就无法再次修改
let user: {
readonly firstName: string
} = {
firstName: 'abby'
}
user.firstName = 'martin' // 报错
Aliases, Unions, Intersections
type Age = number
type Person = {
name: string,
age: Age
}
type Cat = {
name: string,
purrs: boolean
}
type Dog = {
name: string,
barks: boolean,
wags: boolean
}
type CatOrDog = Cat | Dog
type CatAndDog = Cat & Dog
let b: CatAndDog = {
name: 'martin',
barks: false,
purrs: false,
wags: false,
}
// b是cat和dog的intersection,所以要有cat和dog的全部属性
Array
数组的类型检查
let f = ['red']
f.push('blue')
f.push(true) // error
let g = []
g.push(1)
g.push('red')
g.push({x: "y"}) // 任何类型都能存入g
let h: number[] = []
h.push(1)
h.push('red') // error, 前面已经声明了只能存number类型
Tuples
// rest elements
let list : [number, boolean, ...string[]] = [1, false, 'a', 'b', 'c']
Function
用…接收任意数量的参数
function sumVariadicSafe(...numbers: number[]): number {
return number.reduce((total, n) => total + n, 0)
}
sumVariadicSafe(1, 2, 3) // 输出6
函数的type aliases
type log = (message: string, userId?: string) => void
let log: Log = (
message,
userId = 'Not signed in'
) => {
let time = new Date().toISOString()
console.log(time, message, userId)
}
Generic Types(泛型)
type Filter = {
<T>(array: T[], f: (item: T) => boolean): T[]
}
let myFilter: Filter = (array, f) => array.filter(f)
// use myFilter function
console.log(myFilter([1, 2, 3], _ => _ > 2)) // output is 3
console.log(myFilter(['a', 'b'], _ => _ !== 'b')) // output is ['a']
let names = [
{firstName: 'Beth'},
{firstName: 'Caitlin'},
{firstName: 'Xian'}
]
console.log(myFilter(names, _ => _.firstName.startsWith('B'))) // output is [{firstName: 'Beth'}]
泛型定义的几种方式
type Filter1 = {
<T>(array: T[], f: (item: T) => boolean): T[]
}
type Filter2<T> = {
(array: T[], f: (item: T) => boolean): T[]
}
// 不同在于Filter2会限制类型
map函数定义就是一个泛型函数,把T类型的数组转换成U类型的数组
function map<T, U>(array: T[], f: (item: T) => U): U[] {
let result = []
for (let i = 0; i < array.length; i++){
result[i] = f(array[i])
}
return result
}
Classes
以国际象棋♟️这个游戏为例
class Game{}
class Piece{}
class Position{}
class King extends Piece{}
class Queen extends Piece{}
class Bishop extends Piece{} // 象
class Knight extends Piece{} // 马
class Rook extends Piece{} // 车
class Pawn extends Piece{} // 兵
type Color = 'Black' | 'White' //黑白两方
type FileVal = 'A'|'B'|'C'|'D'|'E'|'F'|'G'|'H' // 8列
type RankVal = 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 // 8行
class Position {
constructor(
private file: FileVal,
private rank: RankVal,
){}
distanceFrom(position: Position) {
return {
rank: Math.abs(position.rank - this.rank),
file: Math.abs(position.file.charCodeAt(0) - this.file.charCodeAt(0)) // 因为file是用字母表示的,所以要UniCode码相减。
}
}
}
class Piece {
protected position: Position // protected类型可以在本类或子类中被访问
constructor(
private readonly color: Color,
file: FileVal,
rank: RankVal
) {
this.position = new Position(file, rank)
}
}
// abstract class,可以实现方法或者抽象方法,抽象类不能被直接实例化,子类(非抽象类)可以被实例化
abstract class Piece {
moveTo(position: Position) {
this.position = position
}
abstract canMoveTo(position: Position): boolean
}
// 抽象类中的抽象方法一定要在非抽象子类中实现
class King extends Piece {
canMoveTo(position: Position) {
let distance = this.position.distanceFrom(position)
return distance.rank < 2 && distance.file < 2
}
}
// 对于一个类,其中的static方法只被创建一次,而不是每次实例化对象都被创建一次。
class Game {
private pieces = Game.makePieces()
private static makePieces() {
return [
new King('White', 'E', 1),
...
]
}
}
Interfaces
接口提供了另一种定义对象的方式
type Sushi = {
calories: number
salty: boolean
tasty: boolean
}
// 等价于
interface Sushi {
calories: number
salty: boolean
tasty: boolean
}
前面说过type可以进行intersection或union。interface也可以做到
type Food = {
calories: number
tasty: boolean
}
type Sushi = Food & {salty: boolean}
interface Food {
calories: number
tasty: boolean
}
interface Sushi extends Food {
salty: boolean
}
class可以实现接口,举例:
interface Animal {
eat(food: string): void
sleep(hours: number): void
}
interface Feline {
meow(): void
}
class Cat implements Animal {
eat(food: string) {
console.info('Ate some', food, '. Mmm!')
}
sleep(hours: number) {
console.info('Slept for', hours, 'hours')
}
}
// 类也可以实现多个接口
class Cat implements Animal, Feline {
// ...
}
Kubernetes
K8s,是一个开源的容器编排系统,用于自动化计算机应用的部署、扩展和管理。
最流行的容器编排软件就是Kubernetes,它在数据中心服务器上运行,抽象掉了底层硬件的复杂性,为运行容器提供了一个简单的接口。正因如此,K8s经常被比作数据中心的操作系统。
Kubernetes
K8s最初使用Docker作为他的容器运行时。
CRI & OCI
CRI全称Container Runtime Interface,OCI全称Open Container Initiative standard
CRI是一种插件接口,它使Kubernetes能够与各种容器运行时进行通信和管理。CRI 提供了一个清晰的界面,使得Kubernetes可以支持多种容器运行时,而不需要每次添加或更新运行时都修改Kubernetes的核心代码。这极大地提高了Kubernetes的模块化和可维护性。
OCI是一个致力于创建开放的容器格式和运行时标准的项目。OCI成立的目的是为了保证容器的开放性和可移植性,使得基于容器的技术可以在不同的环境和平台之间无缝运行,无论是物理服务器、虚拟机、私有云还是公有云。
微服务和单体架构(Microservices & Monoliths)
单体架构是一种传统的软件开发模式,其中应用的所有功能都被集成到一个单一的、独立的部署单元中。在这种架构中,应用的客户端界面、后端逻辑和数据库访问都构成了一个紧密耦合的单一代码库。方便部署运维,但是扩展性首限
微服务架构是一种将应用分解为一组较小、独立服务的方法,每个服务执行应用的一个具体功能,并且独立部署。每个微服务通常围绕业务能力构建,运行在自己的进程中,服务之间通常通过网络调用进行通信。灵活可扩展,而且单个服务的失败不会影响整个应用。
K8s集群由一组机器(节点)组成,每个节点上都运行容器化的应用。节点有两种类型:control plane和worker nodes。control plane负责管理集群,worker nodes负责运行容器。
K8s集群架构如下图所示
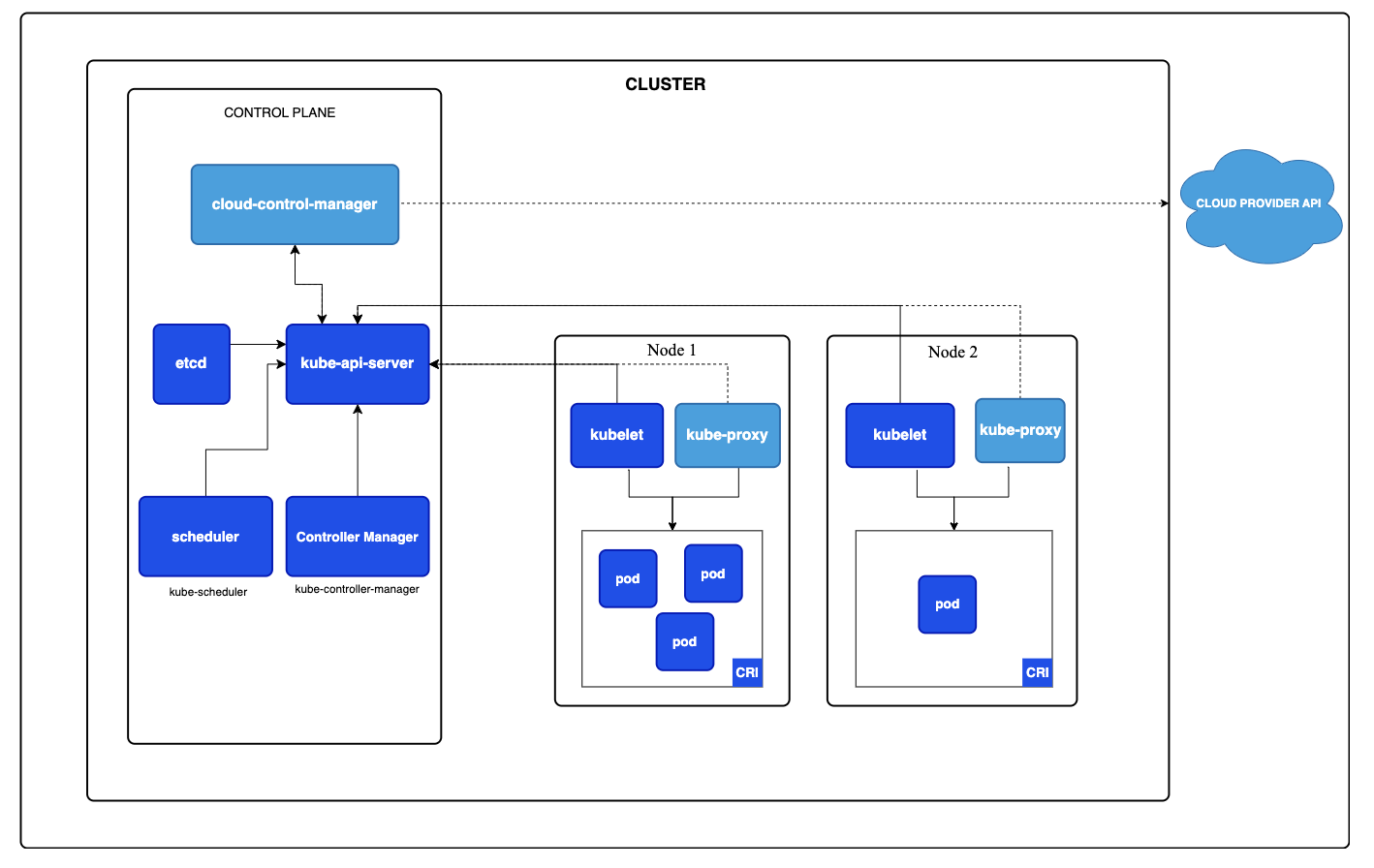
Control Plane
Control Plane包含以下组件
- API Server相当于control plane的前端,暴露一个RESTful API。用户使用这个API和集群交互,内部也用这个API来彼此通信。
- Cluster Store是一个键值存储,管理集群的状态。K8s中最常用的Cluster store就是etcs,一个高可用键值存储。
- Scheduler调度作业,它会考虑一个任务的资源需求,每个节点上可用的资源量,如果找不到满足需求的节点,任务会持续pending直到有合适的节点出现。pending状态的任务能触发集群中节点数量的提升。
- Controllers处理集群中的例行任务,一些主要的controller
- Deployment controller
- StatefulSet controller
- ReplicaSet controller
- Controller Manager管理Controllers
Worker Nodes
Worker nodes可以处理容器的执行。它包含以下组件
- kubelet: 这是运行在所有 Kubernetes 节点上的主要节点代理。它负责启动、停止和管理容器(通过容器运行时)、维护容器的生命周期、执行如健康检查之类的操作,并与 Kubernetes 的控制平面通信,以报告节点上的资源使用情况和状态信息。
- Container runtimes: 这是实际运行容器的软件。Kubernetes 本身不直接创建或运行容器,而是依赖容器运行时。常见的容器运行时包括 Docker、containerd 和 CRI-O。这些运行时负责镜像管理和容器执行。
- Apkube Proxy: 运行在每一个worker node上,给节点提供网络。
Canary releases
Canary releases 是一种软件发布策略,目的是通过将新版本软件推送到一小部分用户中,来测试其性能和稳定性。这种策略可以帮助开发团队识别和解决潜在的问题,而不会影响到所有用户。
Set up Kubernetes Cluster
由于kubeadm工具的存在,Kubernetes集群很容易设置,有两种指令来初始化
kubeadm init这个命令初始化Kubernetes control-plane node。kubeadm join这个命令初始化Kubernetes worker node并把它加入集群。
禁用Swap和SELinux
在Linux中,swap space(交换空间)是硬盘上的一部分空间,用作当物理内存(RAM)使用完时的备用存储。当系统的RAM被完全使用时,较少使用的数据可以被临时转移到swap空间,从而为需要更频繁访问的数据腾出空间。Kubernetes不支持交换空间的存在,如果检测到交换内存,kubelets会失败。
如何在master和worker nodes上禁用SELinux? 需要编辑/etc配置文件,修改成SELINUX=disabled
reboot命令用来重新启动系统使一些改动生效。