Week1
高性能计算的目标
- 对于有限的数据集,最小化解决时间
- 对于无限的数据集,最大化吞吐量(throughput)
- 有能力解决一些对于可用的内存来说太大的问题
- 最大化资源利用 - CPU/内存/网络/加速器(GPU)/电力
一些常用术语
- Parallelism vs Concurrency
- Parallelism: 多个进程同时且独立执行
- Concurrency: 多个进程同时执行且共享至少一种资源
- Processor, Die & Socket
- Processor: 执行程序指令的电路。计算机系统中可能有许多处理器,例如图形处理器、视频处理器。在没有限定的情况下,通常指中央处理器
- CPU: 计算机系统中主要的通用处理器(之一),而非特定用途(如视频解压缩)。
- Die: 指硅晶片,包含处理器(通常是中央处理器)以及接口所需的其他组件(如内存控制器)。
- Socket: 处理器和计算机主板之间的物理接口,它定义了处理器与主板连接的方式。不同的处理器和主板可能需要不同类型的Socket。
- Core & Thread
- Core: 核心是CPU内部的一个物理处理单元,能够独立执行计算任务。每个核心可以独立处理指令和执行计算操作。
- Thread: 线程是操作系统能够进行计算调度的最小单位。它是程序执行流的一个单一顺序,可以被操作系统调度(启动、停止、挂起等)。
- 核心和线程共同定义了处理器的处理能力
- Node
- 指一个服务器节点(一台计算机)
- Cluster/Supercomputer
- 成百上千个节点组成集群
- Single precision floating-point
- 通常占用32位(4字节)的存储空间,C语言中的float32类型,1符号位,8指数位,23有效数字位
- Double precision floating-point
- 通常占用64位(8字节)的存储空间,C语言中的float64类型,1符号位,11指数位,52有效数字位
- Flop
- Floating-point operations per second
如何量化/评估性能
公式如下👇
$R_{peak} = 2\times w_{vec} \times r_{clock} \times n_{core} \times n_{socket}$
变量解释:
- $R_{peak} - $峰值理论性能
- $w_{vec} - $向量宽度,表示每个处理器核心每个时钟周期内可以执行的浮点运算数。
- $r_{clock} - $表示处理器核心每秒钟可以执行的时钟周期数。
- $n_{core} - $表示单个处理器(CPU)或计算节点中的核心数量。
- $n_{socket} - $表示系统中处理器(CPU)的数量。
Linpack性能测试:Linpack性能测试是一种衡量计算系统解决高密度线性代数问题能力的测试。这个测试通过测量系统在执行大规模双精度(64位)浮点算术矩阵运算时的性能来评估计算机的速度和效率。Linpack测试的一个典型应用是计算给定大小的矩阵$A$和向量$b$,求解线性方程组$Ax = b$
Week2
Plot programs performance
用"Arithmetic Intensity",记作$I(n)$,来评估性能。$I(n) = {W(n)\over Q(n)}$。
$W(n)$:程序执行flops的次数,$Q(n)$:从内存传输到缓存的字节数。
- 低Arithmetic Intensity的程序叫内存受限程序
- 高Arithmetic Intensity的程序叫计算受限程序
- 对于内存受限的程序,处理器需要花费更多时间等待操作数从内存中传送出来(更多的时间花费在访问内存上,而不是运算上)。
Roofline Model
Roofline Model是帮助了解软件性能的可视化工具。
Roofline Model两个组成部分
- 峰值性能($R_{peak} / R_{max}$):这是计算系统在理想情况下可以达到的最高计算性能,通常以每秒浮点运算次数(FLOPS)来衡量。峰值性能由处理器的硬件特性决定,比如核心数量、时钟频率和向量化能力。图中水平线就是峰值性能
- 内存带宽(Memory Bandwidth):这是计算系统在单位时间内能从内存中读写数据的最大速率,通常以每秒传输的字节数(Bytes/s)来衡量。内存带宽是由系统的内存架构和内存类型决定的。带角度的斜线表示内存带宽
冯·诺伊曼
Von Neumann架构图如下所示👇
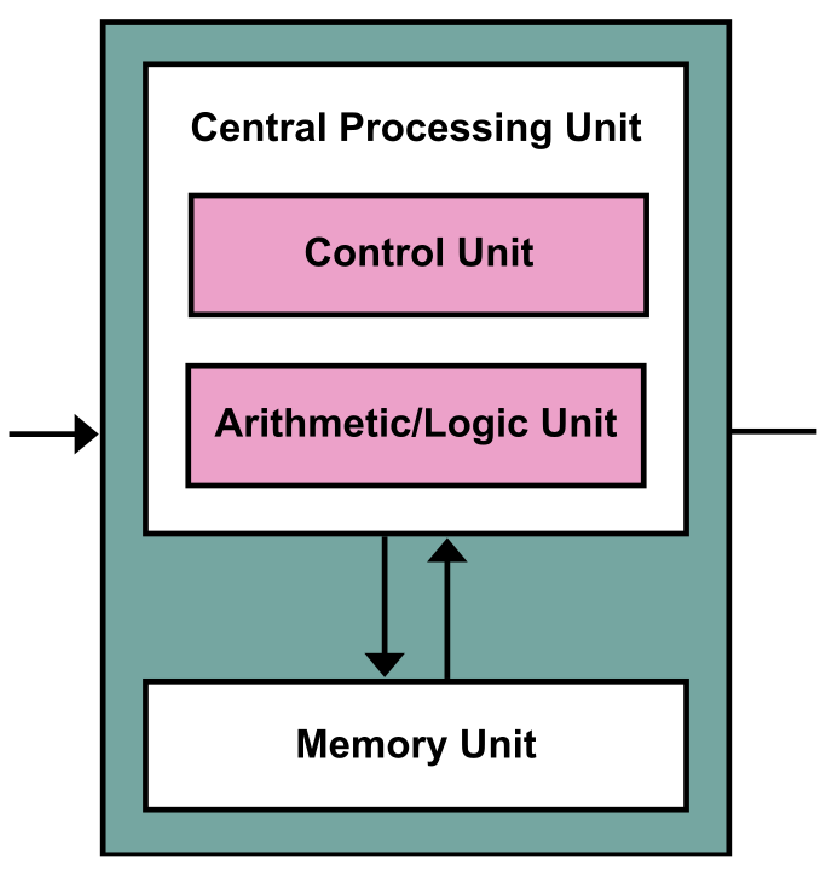
- 由控制单元和算术/逻辑单元组成的CPU。
- 独立的存储区,可存储指令和数据。
- 指令由CPU执行,因此必须将指令从存储器带入CPU。
- 数据也必须从存储器进入CPU才能执行。
- CPU包含寄存器,作为临时存储的刮板。
- The von Neumann bottleneck: 数据和指令共用一条总线,因此指令获取和数据操作不能同时进行。
冯·诺伊曼瓶颈
- 从内存中抓取对应程序计数器的指令
- 解码指令
- 从内存中抓取数据
- 执行指令
- 写回结果
Pipelining
Pipelining的基本概念
流水线技术通过将指令的执行过程分解为多个阶段,并让不同的指令在不同的时间并行处理这些阶段来提高处理速度。这就好比是在组装线上,每个工人负责组装线上的一个特定任务,产品可以更快地完成,因为多个任务是在同时进行,而不是一个接一个地完成。
在von neumann cycle中的应用
在应用流水线技术后,处理器可以在完成当前指令的某个阶段的同时,开始执行下一条指令的前一个阶段。例如,当第一条指令在执行阶段时,第二条指令可以同时进行译码,第三条指令可以进行取指。这样,虽然每条指令的执行仍然需要串行经过所有阶段,但处理器可以在同一时刻处理多条指令的不同阶段,从而大大提高了指令的吞吐率。
对抗冯·诺伊曼瓶颈的方法
在芯片上添加高速缓存(cache),但高速缓存也存在问题
例如,高速缓存越大,数据访问速度越慢。可以采用多级缓存架构,通过在处理器和主内存之间引入多个层级的缓存,旨在平衡缓存大小、访问速度和命中率之间的关系。
高速缓存利用了程序的空间局部性(spatial locality)和时间局部性(temporal locality)。
- 时间局部性指的是在较短的时间内,被访问过一次的数据项很可能在不久的将来再次被访问的特性。这种访问模式意味着一旦数据被加载到缓存中,它很可能很快再次被需要,因此保留这些数据项在缓存中可以减少对较慢主存的访问次数。
- 空间局部性是指如果一个数据项被访问,那么其附近的数据项很快也可能被访问的特性。这种模式基于数据存储的物理结构,相邻的数据项通常也在内存中相邻存储。高速缓存系统利用这一特性通过预取附近的数据项到缓存中,即使这些数据项还没有被显式请求。
AMD Bulldozer 服务器插槽的内存层次结构
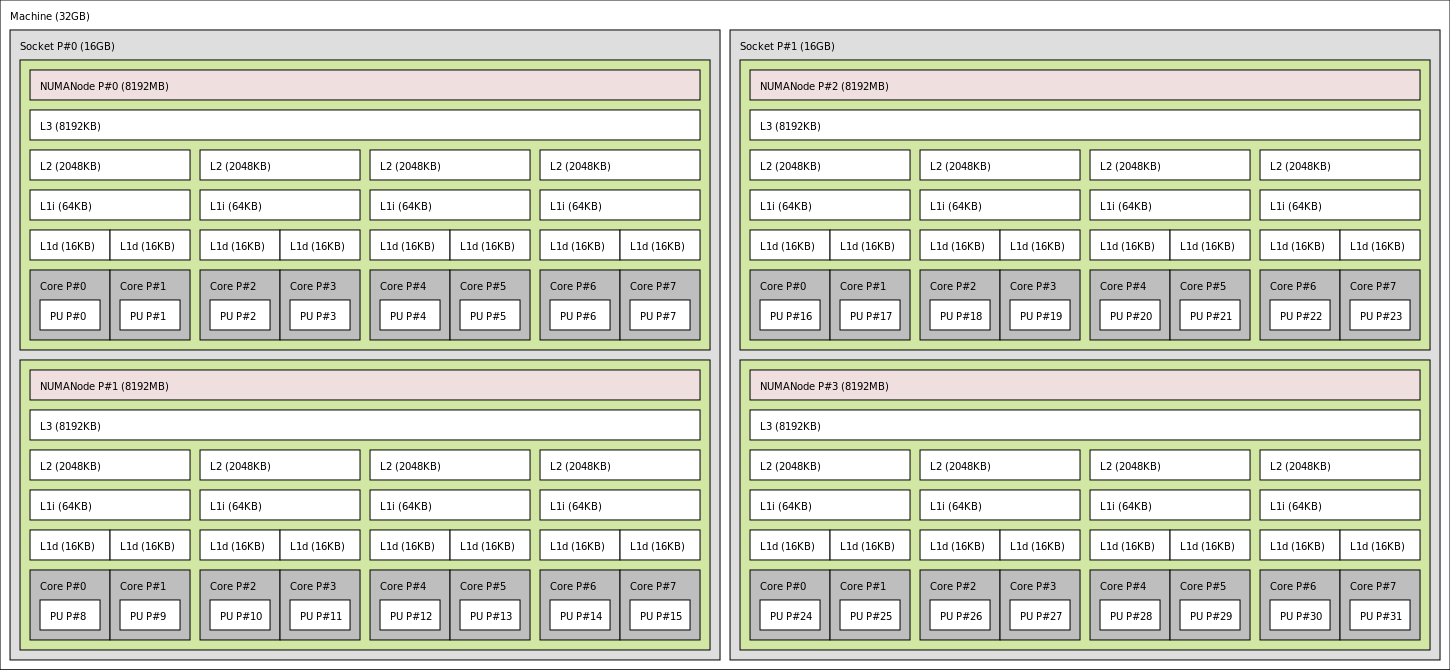
How to gain performance form a single core/socket
for (int i = 0; i<1000; i++) {
b[i] = a[i]*a[i];
}
对于上面这个程序,应该运行1000个clock cycles。假如一个clock cycle不是做一次迭代,而是做4次迭代,那么总共需要250个clock cycles。这就叫vector processing,也叫Single Instruction, Multiple Data(SIMD)。
在单核上压榨更多性能:SMT(simultaneous multithreading),通过在单个物理CPU核心上同时执行多个线程来提高处理器的效率和性能。SMT允许单个核心像操作系统和应用程序呈现出多个逻辑核心或线程,使得处理器可以更有效地利用其资源,特别是在一个线程等待数据访问或执行长时间操作时,处理器可以转而执行另一个线程的任务。
Week3
编译器优化的常用方法
两种优化方式:
- 时间优化
- 空间优化
编译器会自动的做一些优化。
von Neumann cycle中的执行阶段也需要对内存进行读写。所有的算术操作都需要读写交替进行。编译器的工作就是给特定硬件确定合理的交错顺序。
读数据的方式对性能表现来说很重要(cache的存在就是为了减少处理器访问主存的次数)。
把多维数据存储成单维数据的两种方法
- row major,C/C++/Java通常用row major
- column major,Fortran/Pascal通常用column major
常用优化方法
- Inlining
float add(int a, int b){
float results = a + b;
return result;
}
int main(NULL){
float a = 3.6;
float b = 6.3;
float result = add(a, b);
}
编译器会把所有的函数用inline code代替,消除函数调用的开销,包括压栈、跳转和返回等操作。Inlining后👇
int main(NULL){
float a = 3.6;
float b = 6.3;
float result = a+b;
}
缺点:如果一个函数在多个地方被内联,那么可执行文件的大小可能会增加,这有时被称为代码膨胀。而且在某些情况下,如果内联导致生成的代码过大,可能会降低指令缓存的效率,反而减慢程序的运行速度。
- Dead code / Dead store
- Dead code: 由于一些条件,这部分代码永远无法执行
- Dead store: 计算过但从未使用过的变量 编译器找到dead code和dead store并安全地忽略他们。
- Code hoisting (代码提升)
for(i = 0; i < N; i++){
x[i] = i * 5 * pi;
}
把常量提出来,防止重复计算👇。!: 过度使用可能会导致寄存器溢出
v = 5 * pi;
for(i = 0; i < N; i++){
x[i] = i * v;
}
- Common Sub-expression
y = a * log(x) + pow(log(x), 2);
👇
v = log(x);
y = a * v + pow(v, 2);
- Loop unrolling
for(i = 0; i < N; i++){
x[i] = i * 5 * pi;
}
👇
x[1] = 1 * 5 * pi;
x[2] = 2 * 5 * pi;
x[3] = 3 * 5 * pi;
...
x[N] = N * 5 * pi;
以上优化方式都是基于时空交换(time-space trade-off)。通常想节省执行时间就要增加代码体量。通常优化程度越高,编译时间越长,可执行文件越大。
生成优化报告
Compiler的优化指令
- -O0/-O 禁用所有优化
- -O1 使用最简单的优化方法
- -O2 所有O1的优化方法,再加一些更高级的优化方法,这里开始出现时空交换的优化方法。Recommended
- -O3 比O2更强劲,涉及大量的时空交换方法,编译时间显著增加,建议用于有密集浮点运算循环的代码
- -Os 针对可执行文件的大小进行优化
- -O2-no-vec 没有vectorisation的O2优化
Intel的生成报告指令
-qopt-reportN,N=0,1,2,3,4,5。0表示没有报告,5表示最详尽的报告
icc program.c -qopt-report3
利用Profiling code确定优化位置
Profiling: 测量程序的行为和性能,包括运行时和资源利用情况。对程序进行细分并找到热点部分,对热点部分进行优化。
分析热点部分:
- 内存带宽?
- 寄存器的数量?
- cache利用率?
- 代码太烂?
Week4
如何实现parallelising a program
- 识别parallelism机会
- 选择parallelism策略
- 使用工具和库(OpenMP, CUDA…)
- 实现+调试
- 性能测试+优化
把问题拆解成并行组件的普遍方法
- Data parallelism
- Task parallelism
- Pipelines
- Mixed Solutions
粒度
- 粗粒度parallelism 粗粒度并行涉及较大的任务,每个任务包含相对较多的计算量。这种并行度较低,因为程序被分解成较少的、但每个都比较大的部分,在多个处理单元上执行。相比于细粒度并行,粗粒度并行的管理和通信开销相对较低,因为任务之间的交互较少。
- 细粒度parallelism 细粒度并行指的是由很小的任务组成的并行计算,每个任务执行的计算量相对较少。它允许高度的并行度,因为程序被分解成许多小的部分可以在多个处理单元上并行执行。细粒度并行的挑战在于管理和协调大量小任务的开销可能会很大,特别是当通信和同步成本高于任务执行成本时。
衡量并发性能
并行编程模型
- Shared Memory Programming: 在共享内存编程模型中,所有处理器都访问同一个物理内存空间。这意味着所有的并行执行线程都可以直接读写同一块内存地址空间中的数据。这种模型简化了数据的共享,因为不需要显式地在处理器之间传递消息来共享数据。共享内存模型通常用于多核处理器或多处理器计算机系统,其中所有核心都能够访问同一个全局内存。OpenMP就是共享内存并行编程的API
- Distributed Memory Programming: 在分布式内存编程模型中,每个处理器或计算节点拥有自己的局部内存,处理器之间通过网络或总线传递消息来交换数据。这种模型要求显式地在不同的处理器之间发送和接收数据,通常使用消息传递接口(如MPI)来实现。分布式内存模型适用于计算集群、多处理器系统或网络连接的计算机,每个节点运行其进程并通过消息传递进行通信和数据共享。MPI(Message Passing Interface)就是分布式内存并行编程标准,对共享内存也适用。
Scalability and Speedup
Speedup指不用并行编程运行程序所花的时间和使用并行编程运行程序所花的时间的比值
Scalability指多添加一个核/处理器的情况下,speedup会有多少提升
$t_1$: 程序在单核(或单处理器)上运行的时间。
$t_p$: 程序在p个核心(或处理器)上运行的时间。
$S_p = {t_1\over t_p}$: 加速比是衡量并行程序相对于其顺序版本的性能提升的指标。理想情况下,当你用p个处理器来运行程序时,程序的执行时间会变为单处理器上的$1\over p$,然而,由于通信和同步开销以及代码中不可并行化的部分,实际加速比往往低于p。
并行效率公式$e_p = {S_p\over p}$: 并行效率是衡量加速比相对于使用的处理器数的效率。它显示了并行资源的利用程度,通常表示为百分比。
Multi-node scaling measurements
- Weak Scaling: 在弱扩展性测试中,随着节点数量的增加,每个节点上的工作负载保持不变。理想情况下,总体工作负载随节点数线性增加,执行时间保持恒定。这样可以测量系统增加计算资源时维持相同性能的能力。
- Strong Scaling: 强扩展性是指总体工作负载保持不变,而节点数增加。理想情况下,执行时间随节点数的增加而减少。这种测量体现了系统处理固定大小工作负载的效率。
Amdahl’s Law 程序的最快执行速度受限于那些必须串行执行的代码部分。这些串行部分的总执行时间设置了程序加速的下限。无论并行处理多么高效,总体性能提升永远不能超过这个下限。
- $\alpha$原始问题中串行部分所占的比例(就时间而言)
- $t_p = {\alpha\times t_1 + {(1-\alpha)\times t_1\over p}}$
- $S_p = {t_1\over t_p} , limit = {1\over\alpha}$
- 最大可能的speedup是$1\over\alpha$
Gustafson’s Law Gustafson’s Law的出发点是,随着处理器数量的增加,人们倾向于解决更大规模的问题,而不是简单地加速固定大小的问题。因此,他认为:
- 总工作量的增加:随着处理器数量的增加,我们不仅仅是将相同的任务分配给更多的处理器,而是增加了总体的工作量,以便填满并利用所有可用的计算资源。
- 串行部分的影响减少:当总工作量增加时,程序中的串行部分所占的比例变得不那么重要,因为绝对的串行处理时间相对于总处理时间的影响变小了。
- 并行部分的增加:与此同时,可并行化的部分在总工作量中占据了更大的比例,因为这些部分可以在所有的处理器上同时进行。
- Speedup = $\alpha + p(1-\alpha)$
Week5
并行解决方案的正确性
Round-off error
在数值计算过程中,由于对数值进行四舍五入或截断导致的误差。当我们使用有限位数的数字来表示和处理无限小数或者非常大或非常小的数时,就必须对这些数进行四舍五入或截断,以适应计算机或计算设备的存储和处理能力。这种处理过程中不可避免地会引入一些误差,这种误差就是round-off error。
克服round-off error:
- 尽量用双精度浮点数而不用单精度浮点数
- 设置一些忍耐度,允许误差存在,例如
if(var1 < var2 - tolerance)
DeadLock and LiveLock
- 死锁是指两个或两个以上的进程在执行过程中,因为争夺资源而造成的一种相互等待的现象,若无外力干涉那它们都将无法向前推进。这种情况下,涉及的进程都在等待其他进程释放资源,但没有一个进程能够向前推进,因为它们都在等待。
- 活锁是指两个或更多的进程在尝试解决某个问题时,由于各进程的反应导致彼此之间不断地改变状态,但实际上没有任何进展。这种情况下,涉及的进程没有被阻塞,它们能够响应其他事件,但是这些进程的状态更改是徒劳的,因为这些更改只会导致问题再次出现,使得系统无法继续向前发展。
Race conditions
程序的行为依赖于某些事件或进程的顺序或时间。当多个进程或线程访问和改变共享数据,并且最终结果取决于这些进程或线程的执行顺序时,就可能发生竞态条件。简而言之,竞态条件发生在两个或多个操作必须以正确的顺序执行,但程序的设计没有正确地序列化这些操作,导致结果不可预测。
Multiple-write race conditions 多写竞争条件发生在多个线程试图同时写入同一个共享变量时。这会导致数据不一致或冲突。解决方案如下
- 线程本地变量副本:每个线程维护一个共享变量的本地副本,最终进行汇总。
- 访问控制机制:使用锁等机制保护变量,使每次只有一个线程可以访问。
- 使用“原子”操作支持:编程语言运行时、操作系统或硬件可能支持“原子”操作,即底层系统实现了访问控制以避免竞争条件。
- 重新设计算法:通常最好的解决方案是重新思考算法,确保避免出现竞争条件的情形。
SIMD
一种并行计算的架构,用于同时在多个数据点上执行相同的操作。在硬件层提供data-parallelism right
Intel的SSE(Streaming SIMD Extensions)和AVX(Advanced Vector Extensions)是针对x86处理器系列的指令集扩展,专门设计来提高特定类型计算的性能,主要是通过SIMD(Single Instruction, Multiple Data)技术实现的。这些扩展通过允许单个指令同时操作多个数据点。
MIMD
在MIMD体系结构中,每个处理器或处理单元可以独立执行其指令流,并且可以操作自己的数据。这种设计允许更大的灵活性和效率,因为每个处理器都可以根据需要独立地执行任务,而不必等待其他处理器的同步。MIMD架构可以是共享内存模型,也可以是分布式内存模型:
- 共享内存模型:在这种模型中,所有处理器都可以访问同一个全局内存。虽然这简化了数据共享和通信,但也可能导致内存访问冲突和同步问题。
- 分布式内存模型:每个处理器有自己的本地内存,处理器间必须通过消息传递来交换信息。这种模型通过减少对共享资源的竞争来提高可扩展性,但增加了编程的复杂性。
OpenMP
介绍
一个并行编程模型
- Thread-based parallelism
- Targeted at shared memory and also accelerations
- 共享内存:OpenMP 设计主要针对共享内存架构,其中所有线程可以访问同一内存地址空间,这简化了数据的共享和通信。
- 加速器支持:OpenMP 也支持各种加速器,如英特尔的 Xeon Phi 和各类 GPU。这意味着你可以使用 OpenMP 将计算任务分发到这些高性能设备上,进一步加速程序的执行。
- Parallelisation using work-sharing and tasks
- 工作共享:OpenMP 通过工作共享构造自动分配循环的迭代到多个线程上。简化了循环并行化的过程。
- 任务:OpenMP 的任务构造允许程序定义可并行执行的独立任务块,提供了更细粒度的并行控制。
- Possible to have a single source code for serial/parallel)
- 一个重要的 OpenMP 特性是它允许同一源代码用于串行和并行执行。通过简单地添加或移除特定的编译器指令,程序可以在不同的模式之间切换,这极大地提高了代码的可维护性和可扩展性。
- Only needs different compiler arguments to switch
- 易于切换:要启用 OpenMP 并行,通常只需向编译器传递一个参数(如 -fopenmp),这会激活编译器中的 OpenMP 支持并并行化那些标记了 OpenMP 指令的代码块。这使得从串行代码到并行代码的转变非常简单。
编译指令
- Intel
icc –qopenmp myFile.c -o output.exe - GNU
gcc –fopenmp myFile.c –o output.exe - 运行指令
OMP_NUM_THREADS=4 ./output.exe
The fork-join model
一种常见的并行设计模式
Fork
- 在“fork”阶段,master thread创建一系列新的并行子线程。这些子线程可以同时执行任务,例如处理数据的不同部分或执行独立的计算任务。
Join
- 在“join”阶段,这些并行执行的子线程完成它们的任务后,会被重新汇合(同步)。master thread在继续执行之前,会等待所有子线程完成。这保证了所有并行任务都已完成,从而允许程序正确地继续执行后续的序列操作。
怎么开始一个parallel region?
//...serial code
#pragma omp parallel
{
int numThreads = omp_get_num_threads();
for(int i = 0; i < numThreads; i++){
printf(“Thread %d says Hello”, i);
}
}
//...serial code
一些工具函数
// 当前并行区域的线程总数
omp_get_num_threads();
// 当前线程的编号
omp_get_thread_num();
// 对后续将要创建的并行区域所可能使用的最大线程数的预估值。
omp_get_max_threads();
relication的含义
#include <stdio.h>
#include <omp.h>
int main() {
int x = 10;
#pragma omp parallel private(x)
{
x = omp_get_thread_num();
printf("Thread %d has x = %d\n", omp_get_thread_num(), x);
}
// 退出并行区域后,原始的x值不变,每个线程的修改仅限于其副本
printf("Outside parallel region, x = %d\n", x);
return 0;
}
输出如下
$ ./replication
Thread 2 has x = 2
Thread 3 has x = 3
Thread 1 has x = 1
Thread 4 has x = 4
Thread 5 has x = 5
Thread 0 has x = 0
Thread 6 has x = 6
Thread 7 has x = 7
Outside parallel region, x = 10
Clauses
Data Clauses (parallel region中有不同范围的变量)
- shared(x):在parallel region外声明,所有线程隐式共享这个变量
- private(x):在parallel region内声明,只有region内的线程能用这个变量
- firstprivate(x): 用于确保每个线程都有其自己的变量副本,并且这些副本在进入并行区域时使用外部作用域中相应变量的初始值进行初始化。这意味着每个线程在开始执行并行代码块之前,都会从主线程(或外部作用域)那里继承变量的值。
- lastprivate(x): 用于指定在并行区域结束后,某个变量的值应该是由执行最后一次迭代(或最后一个区块)的线程中的对应变量值来更新的。这确保了变量在并行区域完成后能够保留最后一次迭代中的值。
在使用OpenMP进行并行计算时,工作调度的方式对性能的影响很大。
Barrier
在OpenMP中,barrier 是一个同步原语,用于确保在该点之前的所有线程都完成其工作才能继续执行后续的代码。简单来说,barrier 创建了一个同步点,在这个点上,所有的线程都必须到达,然后才能一起继续执行后面的指令。
- 自动屏障:在某些指令,如
#pragma omp for或#pragma omp sections的末尾,OpenMP会自动插入屏障。除非使用nowait子句,否则所有线程在继续之前都必须完成它们的部分。例如#pragma omp for nowait - 显式屏障:可以通过
#pragma omp barrier显式地在代码中插入屏障。
NUMA
Non-Uniform Memory Access(NUMA)是一种计算机内存设计,用于多处理器系统,在该设计中,每个处理器都有自己的本地内存。处理器可以直接访问本地内存(本地访问)比访问另一个处理器的内存(远程访问)更快,因为远程访问需要通过一些内存总线或交换机等更复杂的连接结构。因此,在NUMA架构中,内存访问时间取决于内存位置相对于处理器的位置。
first touch in NUMA 在NUMA(Non-Uniform Memory Access)系统中,“first touch” 是一个页面级内存管理策略,这一策略影响内存分配的位置。这个原则的核心思想是操作系统将内存页面分配给触碰它的第一个处理器的本地内存节点。“触碰"通常是指对内存页面进行写操作。
举例
#pragma omp parallel for
for (int i = 0; i < large_array_size; i++) {
large_array[i] = initial_value; // First touch happens here
}
数组的每个部分由首次写入数据的线程进行初始化,因此内存页面将被分配到与该线程相对应的NUMA节点上。这样,当数组被后续的计算访问时,每个线程大概率访问的是其本地节点的内存页面,减少了远程内存访问,提高了性能。
MPI
一些Vocabulary
- Process: “Process” 是并行计算的基本单位,可以被理解为执行 MPI 程序的一个独立实体。每个 MPI 进程都有自己的地址空间(即独立的内存空间),这意味着进程间不共享内存。因此,MPI 进程之间必须通过消息传递来交换数据,这是 MPI 并行编程模型的核心。
- Communicator: “Communicator” 用于定义一组可以相互通信的进程。Communicator 确定了哪些进程参与到特定的通信中,它为这些进程提供了一个上下文,在这个上下文中,每个进程都有一个唯一的标识符(rank)。这样,Communicator 不仅定义了通信的参与者,还定义了它们之间的通信方式。
- Rank: 每个进程的rank是一个非常重要的概念,它指的是在所有参与通信的进程中每个进程的唯一标识符。Rank是一个从0开始的整数,用于在进程群(通常是在MPI_COMM_WORLD这个全局通信器中)内唯一标识每个进程。
How to compile and run MPI code
#include <stdio.h>
#include <mpi.h>
int main(void) {
int myID;
// initialize MPI environment
MPI_Init(NULL, NULL);
// assign ranks
MPI_Comm_rank(MPI_COMM_WORLD, &myID);
printf(“Hi from process ranked %d\n”, myID);
MPI_Finalize();
}
编译
# For Intel
$ mpiicc <filename>.c
# For GNU
$ mpicc <filename>.c
运行
# Intel and GNU are same
$ mpirun –np <num_process> <executable_file>
MPI的两个重要函数MPI_Send()和MPI_Recv()
int MPI_Send(
const void* buf, // 指向发送数据缓冲区的指针
int count, // 要发送的数据元素数量
MPI_Datatype datatype, // 数据元素的类型
int dest, // 目标进程的rank
int tag, // 消息标签,用于区分不同类型的消息
MPI_Comm comm // 使用的通信器
);
int MPI_Recv(
void* buf, // 指向接收数据缓冲区的指针
int count, // 能够接收的最大数据元素数量
MPI_Datatype datatype, // 数据元素的类型
int source, // 源进程的rank
int tag, // 消息标签
MPI_Comm comm, // 使用的通信器
MPI_Status* status // 用于返回关于接收的消息的状态信息
);
Blocking Communications
阻塞通信指的是在通信操作(如发送或接收消息)完成之前,发起通信的进程会被暂停(阻塞)。
- MPI_Send:在消息完全发送到接收缓冲区之前,发送操作不会完成,发送方进程会被阻塞。
- MPI_Recv:如果没有数据到达,接收方进程将等待,直到消息到达并被完全接收后才继续执行。 阻塞通信简化了程序的编写,因为你可以确信在调用返回后通信已经完成。但是,这种方式可能会导致效率低下,特别是在大规模并行计算任务中,因为它可能导致资源的闲置。
Non-blocking Communications
非阻塞通信允许一个进程发起一个通信操作后立即继续执行其他工作,而不必等待通信操作完成。这种方式可以提高应用程序的并行性。
- MPI_Isend:启动一个发送操作,但立即返回,让发送进程可以继续执行其他计算或发起更多的非阻塞通信。
- MPI_Irecv:开始接收操作,同时允许进程执行其他任务,直到数据到达。
Lab Tips
英文记录了,方便答题。
Lab02
- What is the difference between usigned int and int
- Unsigned int only allows natural numbers, which means it can store larger positive integers.
- If you were to parallelise this program, and divide the problem into different iterations, what may cause an issue in parallel performance?
- Load imbalance would affect this program. Some iterations take longer which means some threads will complete earlier, and wait (do nothing).
Lab03
- What optimisation levels do you think contributed most to the decrease in execution time?
- O2 seemed to produce the biggest decrease in execution time. Even though O1 decreased it the most from the previous (roughly 6000ms to 1400ms) O2 achieved roughly 200ms. This would be because of vectorisation which O2 performs, but not O1. O3 did not reduce the time much after this.
- Why, as the number of cores increased, do you think the scalability began to decrease?
- Multiple reasons, one could be resource contention as more threads begin to access memory locations used by other threads. But considering that mkl is meant to be heavily optimised reducing this, the more likely reason would be Amdahl’s law, as the number of threads increase, the serial portion of the program begins to dominate compared to the parallel time.
Lab04
- Avoiding excessive synchronization in programming is important for several reasons, primarily related to performance and complexity:
- Performance Degradation: Synchronization often means that some operations must wait for others to complete, leading to thread blocking. This waiting reduces the efficiency of program execution. In high-performance computing or applications where response time is critical, such delays are unacceptable.
- Risk of Deadlocks: Improper synchronization can lead to deadlocks, where multiple processes or threads wait indefinitely for each other to release resources, thus halting their execution. Deadlocks are not only difficult to debug but can also cause the program to stop responding entirely.
- Increased Programming Complexity: Implementing and maintaining synchronization mechanisms requires careful design to ensure all threads or processes acquire and release resources at the correct times. This not only complicates the code but also makes debugging and testing more challenging.
- Scalability Issues: Over-reliance on synchronization can limit a program’s scalability on multicore or multiprocessor systems. Synchronization restricts the possibility of parallel execution, potentially underutilizing multiple cores or processors.
- Use mutex to remove race condition
void* mutex_testing(void* param){ int i; for (i = 0; i < 5; i++) { pthread_mutex_lock(&myMutex);/*lock..*/ counter++; printf("thread %d counter = %d\n", (int)param, counter); pthread_mutex_unlock(&myMutex); /*unlock..*/ } } int main() { int one = 1, two = 2, three = 3; pthread_t thread1, thread2, thread3; pthread_mutex_init(&myMutex, 0); pthread_create(&thread1, 0, mutex_testing, (void*)one); pthread_create(&thread2, 0, mutex_testing, (void*)two); pthread_create(&thread3, 0, mutex_testing, (void*)three); pthread_join(thread1, 0); pthread_join(thread2, 0); pthread_join(thread3, 0); pthread_mutex_destroy(&myMutex); return 0; }- Mechanism for Removing Race Conditions
- Locking (pthread_mutex_lock): Before each modification of counter, the thread attempts to acquire the mutex. If the mutex is already held by another thread, the current thread will block until the mutex is released.
- Unlocking (pthread_mutex_unlock): After modifying counter, the thread releases the mutex, allowing other waiting threads to acquire the lock and proceed with their execution.
- Trade-offs and Consequences
- Performance Impact: The use of mutexes introduces synchronization overhead. Acquiring and releasing locks takes time, especially in high-contention environments, where frequent locking operations can lead to significant performance bottlenecks.
- Reduced Scalability: As the number of threads increases, contention for locks can become more frequent, further impacting the program’s scalability. Mutexes can become a bottleneck in scenarios where many threads try to access the same resource, limiting the program’s ability to scale on multiprocessor systems.
- Risk of Deadlocks: Although unlikely in this simple example, improper use of locks in more complex applications (such as acquiring multiple locks in an incorrect order) can lead to deadlocks, causing the program to hang or crash.
Lab05
- Difference between replication and workshare
- Replication refers to duplicating the same computational tasks across multiple processors or computing nodes. In this strategy, every node or processor performs exactly the same code and operations, typically used to enhance fault tolerance and reliability. For example, in a high-availability system, multiple servers might replicate the same request processing tasks to ensure that if one server fails, others can seamlessly take over, thereby improving the overall availability of the system.
- Workshare involves dividing a larger task into smaller chunks, which are then distributed among multiple processors or nodes for parallel execution. Each processor is responsible for a portion of the overall task. This method effectively utilizes the parallel processing capabilities of multicore or multi-node systems to enhance computational efficiency. For example, in parallel loops, iterations of the loop can be distributed among several processors, with each processor handling a segment of the iterations.
Lab06
- What is race condition?
- A condition where the program’s behaviour changes depending on the sequence or timing of events outside the control of the program, non-deterministic results.
- What is false sharing?
- False sharing occurs when 2 threads are accessing the same cache line. When one thread modifies a variable in the cache line, the cache line is considered stale due to how cache lines are designed for serial code. Because of this, data can be stored in.