做了一些初步的调研,脑袋里稍有想法。微调加速可以从两个方面入手,一个是加速训练过程,一个是加速推理过程。看起来加速推理过程要比加速训练受欢迎的多(或许是为了用户体验吧)。而加速训练(例如高速加载训练数据)的工作却寥寥无几(可能是huggingface的datasets太过强大?也可能是我搜索文章的方式不对)。
微调在调什么?
- 全参数微调(FPFT):
- 参数高效微调(PEFT): 这里主要指LoRA。LoRA操作是在hidden layer中添加一些小矩阵层(这两层的连接做的是加法)。输入经过一遍神经网络会产生一个输出,这个输出被用来和期望的输出做比较得出一个损失,然后将这个损失梯度下降反向传播回这个网络,但是在这个反向传播的过程中,原来的hidden layer参数不会再更新,更新的只有加入的LoRA层。反复训练最终得到loRA adapter。
微调加速的前沿工作(FPFT)
RLHF
SFT
数据加速的前沿工作
DataStreaming
微调加速的前沿工作(PEFT)
Huggingface PEFT -> Punica -> S-LoRA -> dLoRA
dLoRA
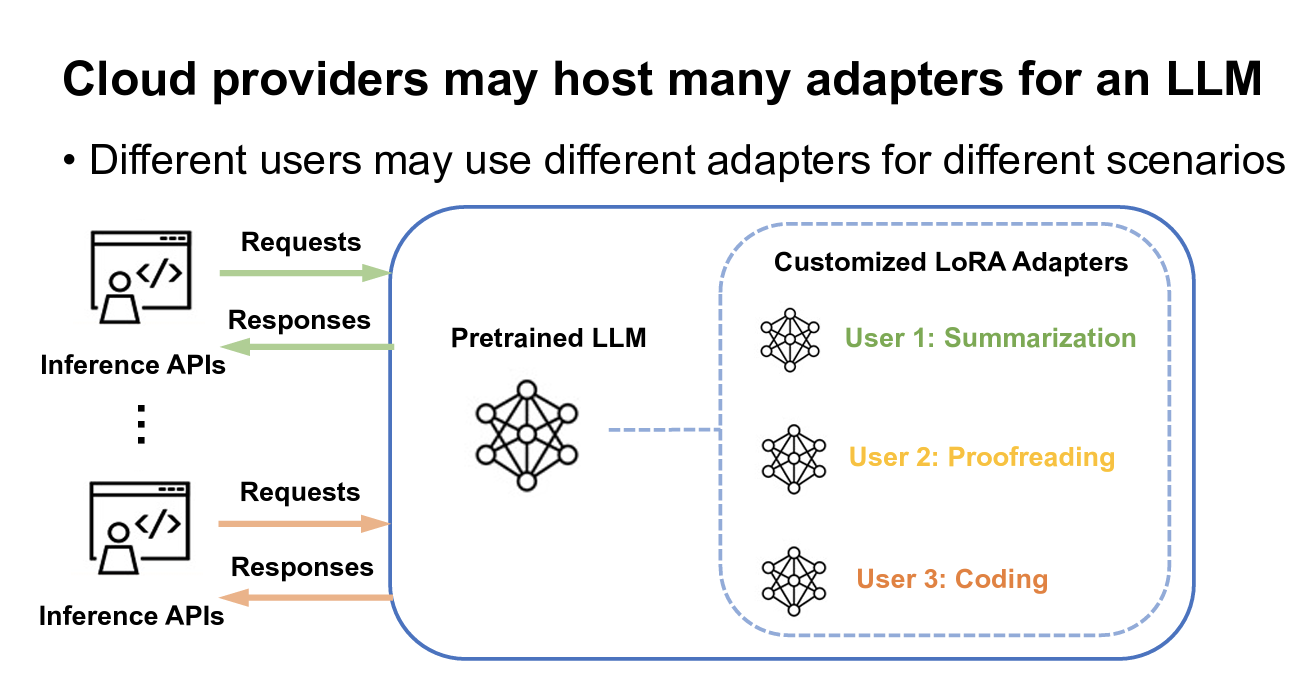
dLoRA 通过动态管理 LoRA adapter和优化推理任务的调度策略,来提升 LLM 的推理效率。他们发现LoRA adapter的推理服务主要面临计算资源利用率低和负载不均衡两个核心挑战。因此如何高效管理多个LoRA adapter成为一个有趣的问题。
 dLoRA的贡献主要有以下两点:
dLoRA的贡献主要有以下两点:
- 在worker level,为了减少端到端的延迟,他们提出了一种技术(dynamic cross-adapter batching technique)来动态切换merged和unmerged模式
- 在cluster level,为了均衡整个集群的负载,他们提出了一种技术(request-adapter co-migration technique)来动态迁移requests和adapters
什么是merged和unmerged模式?
- Merged Adapters 指的是在推理前,将LoRA adapter的权重直接加回原始模型权重,使得推理时不需要额外的矩阵计算。这样做的优点在于减少了计算开销,因为只需要对合并后的权重 $W_{final}$ 进行一次forward计算。如果某个LoRA adapter的请求很多,Merged模型会提升吞吐量。但是这也造成加载模式不够灵活。因为合并后,如果要换成另一个 LoRA Adapter,必须重新加载模型权重,增加开销。
- Unmerged Adapters 指的是在推理时动态计算 LoRA adapter的更新,而不是提前合并进原始模型。这样做适用于多LoRA Adapter的场景,可以动态切换Adapter,多个Adapter共享同一个基础模型,无需重新加载模型权重。但是这会增加计算开销,因为每次推理都要额外计算adapter的推理,比merged mode稍慢。
Dynamic cross-adapter batching technique:
决定什么时候用merged mode什么时候用unmerged mode的策略。这个策略会动态决定切换模式的时间点。具体算法如下图所示。如果某个适配器的请求数量足够多(超过阈值 $\alpha_\text{switch}$),就合并适配器,提高计算效率。如果某个适配器的请求数量变少(低于阈值 $\beta_\text{switch}$),就取消合并,避免浪费计算资源。

固定的阈值不够灵活,如果合并适配器带来的吞吐量提升不明显,就应该降低 $\alpha_\text{switch}$,让更多的请求保持 unmerged mode,提高灵活性。
如果合并适配器显著提高了吞吐量,则应该增加 $\alpha_\text{switch}$,让更多的适配器进入 merged mode。具体算法如下图所示。

Request-adapter co-migration technique: 核心思想就是将LoRA adapters和请求(处于中间态的)从过载的replicas迁移到其他replicas上。
Possible Improvement Points:
dLoRA 作为一个针对 LoRA 适配器推理服务 进行优化的系统,确实在吞吐量、延迟和 GPU 资源利用率方面大幅提升了效率,但它仍然有一些局限性(limitations),并有潜在的改进空间。以下是可能的限制和改进方向:
- 适配器切换的开销 dLoRA 采用了动态调整Merged mode和Unmerged mode的策略,但适配器的频繁切换 仍然会带来计算开销,尤其是在短时间内多个 LoRA Adapter的请求交替频繁到达时,可能会导致额外的适配器加载和迁移成本。 ILP(整数线性规划)用于优化requests-adapter的迁移策略,但求解 ILP 本身的计算开销可能会成为瓶颈,特别是在大规模分布式集群中。所以潜在的改进方向:
- 优化适配器切换策略:目前 dLoRA 主要基于经验阈值来决定何时合并/解耦 LoRA 适配器,这个阈值虽然会自适应调整,但是存在滞后性,如果请求量激增,系统需要多轮迭代后才能适应。
- 减少 ILP 计算开销:采用近似优化(Approximate Optimization)或启发式算法(Heuristic-based Scheduling),替代 ILP 求解,降低计算成本,同时保持较好的负载均衡效果。
S-LoRA
S-LoRA是一种大规模部署LoRA adapters的技术。不涉及merged和unmerged模式之间的调度,它就是用Unmerged模式。S-LoRA关注的点在存储方式。他们提出Unified Paging,压榨显存,使单个GPU能为上千个adapter服务。
Punica
References
[1] Wu, Bingyang, et al. “{dLoRA}: Dynamically orchestrating requests and adapters for {LoRA}{LLM} serving.” 18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). 2024.
[2] Sheng, Ying, et al. “S-lora: Serving thousands of concurrent lora adapters.” arXiv preprint arXiv:2311.03285 (2023).